
{kind=link}
Agentic RL training — Key Takeaways
- Agentic RL optimizes entire decision-making processes through interaction with environments.
- Training in agentic RL involves iterative closed loops for policy updates and reward calculations.
- Initial training of GPT-OSS highlighted issues like exploding KL divergence and unstable rewards.
- Using rollout correction enhances training stability and gradient norm improvement.
- Faster convergence for GPT-OSS-20B has been achieved through enhancements in FlashAttention v3.
What We Know So Far
Understanding Agentic RL
Agentic RL training — Agentic reinforcement learning (RL) expands on traditional large language model (LLM) training by optimizing a comprehensive decision-making process. This optimization is achieved through direct interactions with an environment, allowing models like GPT-OSS to learn and refine their strategies dynamically. As the model engages with diverse scenarios, it develops a nuanced understanding of various decision pathways, enhancing its performance in real-world applications.
Training Dynamics
Training using agentic RL follows a systematic iterative closed loop. Here, the agent interacts with the environment, collects rollout trajectories, computes rewards, and updates its policies accordingly. This approach is vital in enhancing the efficacy of the training process. The closed-loop structure ensures that feedback from the environment is continuously integrated into learning, making the training adaptable and responsive to dynamics.
Key Details and Context
More Details from the Release
The GPT-OSS model has shown comparable performance to OpenAI o3-mini and o4-mini, although its suitability for agentic reinforcement learning training has not yet been validated.
Training follows an iterative closed loop in which the agent interacts with the environment to collect rollout trajectories, computes rewards, and updates policies.
Agentic reinforcement learning (RL) extends traditional LLM training by optimizing an entire decision-making process learned through direct interaction with an environment.
After applying fixes in FlashAttention v3, faster convergence for GPT-OSS-20B across diverse reinforcement learning tasks was observed. The improvements indicate that leveraging advanced techniques can lead to more efficient training protocols.
A substantial token-level probability mismatch was observed between the inference engine and the distributed training stack using different attention kernels. This discrepancy underscores the importance of consistency in model training and inference environments.
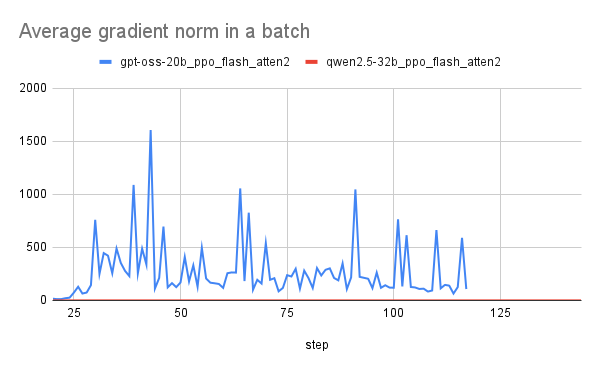
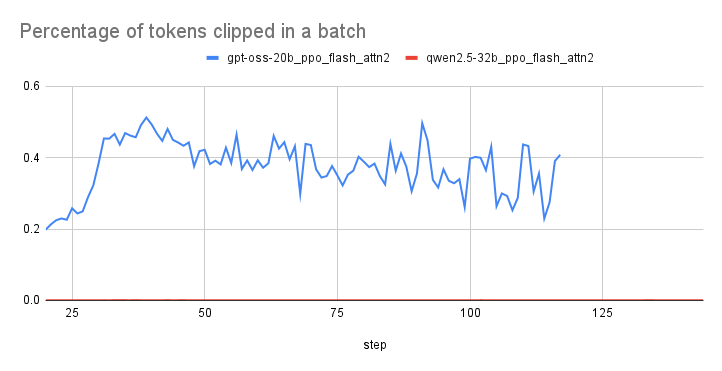
Training with rollout correction improves gradient norms and leads to stable performance compared to runs without rollout correction. Emphasizing this technique ensures that the model can maintain performance even when faced with abrupt changes in training conditions.
The importance sampling ratio must be exactly 1 in pure on-policy Proximal Policy Optimization (PPO). Compliance with this criterion is crucial for achieving reliable results and maintaining the integrity of policy updates.
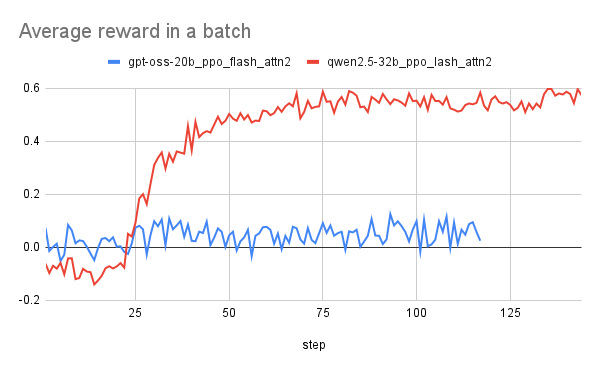
Initial training runs observed exploding KL divergence and entropy, with non-increasing rewards, indicating issues in the GPT-OSS training setup. Addressing these problems is essential for refining the training specifications.
The GPT-OSS model has shown comparable performance to OpenAI o3-mini and o4-mini, although its suitability for agentic reinforcement learning training has not yet been validated. Continuous testing and evaluation is expected to determine its effectiveness in various applications.
GPT-OSS Performance Comparisons
Preliminary comparisons indicate that the GPT-OSS model performs comparably to OpenAI’s o3-mini and o4-mini. However, it is essential to note that the suitability of GPT-OSS for agentic RL training remains to be thoroughly validated. This comparative analysis is expected to guide future enhancements and adaptations of the model.
Challenges Identified
Initial training runs have revealed significant issues such as exploding KL divergence and a lack of stable rewards. This indicates potential problems in the training setup that need addressing for more reliable outcomes. Continuing to refine the training process and methodologies is vital to ensure the model can deliver consistent performance across different applications.
What Happens Next
Stabilizing Techniques
One of the critical aspects of successful training is ensuring that the importance sampling ratio equals 1 in pure on-policy Proximal Policy Optimization (PPO) methods. Achieving this is vital for stable updates during the learning process and minimizes volatility in resulting policy decisions.
Improvements Through Rollout Correction
Utilizing rollout correction has shown to improve gradient norms and lead to more stable performance when compared to training runs that do not incorporate this correction method. This stability is crucial for achieving reliable training outcomes, enabling the model to adapt efficiently to unforeseen challenges during execution.
Why This Matters
Enhancements in FlashAttention v3
By applying fixes in the FlashAttention v3 technique, researchers observed faster convergence for the GPT-OSS-20B model across various reinforcement learning tasks. This advancement suggests that continuous improvements in model architectures can significantly impact performance. Understanding these enhancements may lead to the development of new methodologies in training other models.
Impacts on Reinforcement Learning
The implications of these findings extend beyond just GPT-OSS and touch on broader aspects of reinforcement learning. Successful implementation of agentic RL methods could potentially revolutionize how AI systems interact with and learn from their environments. By creating frameworks that better mimic real-life decision-making, future iterations of models may achieve higher efficiency and adaptiveness.
FAQ
What is agentic reinforcement learning?
Agentic reinforcement learning (RL) is a method that optimizes decision-making processes by learning from direct environmental interactions.
How does training differ for GPT-OSS?
GPT-OSS employs agentic RL techniques, focusing on iterative updates and rollout corrections to stabilize training outcomes.